Architecture
Virtual clusters are fully functional Kubernetes clusters nested inside a physical host cluster. These virtual clusters are designed to provide better isolation and flexibility for optimal multi-tenancy.
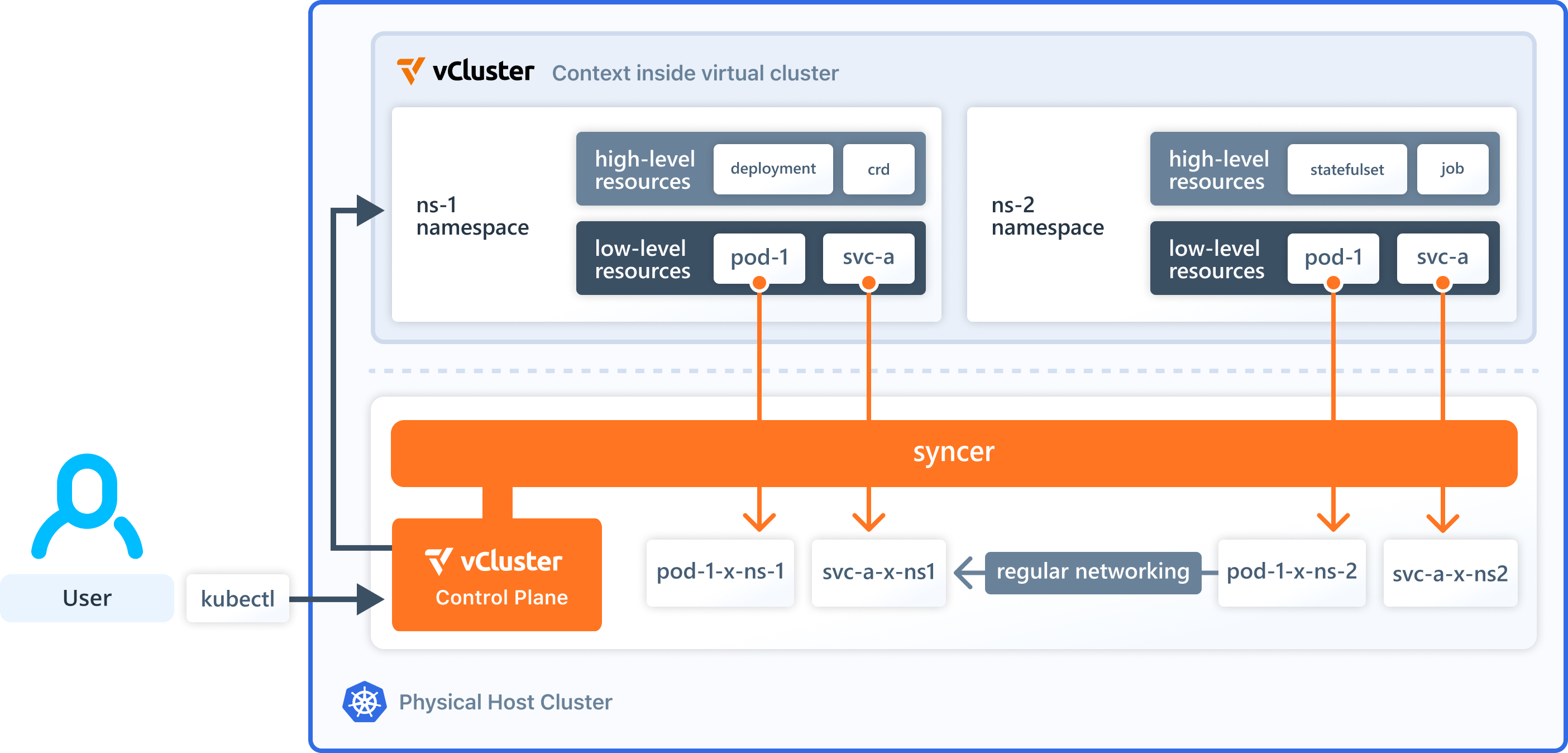
Virtual cluster compoments
Virtual control plane
vCluster creates isolated Kubernetes environments by deploying a virtual cluster that contains its own dedicated virtual control plane. This control plane orchestrates operations within the virtual cluster and facilitates interaction with the underlying host cluster.
The virtual control plane is deployed as a single pod managed as a StatefulSet (default) or Deployment and it has the following components:
- A Kubernetes API server, which is the management interface for all API requests within the virtual cluster. It supports a variety of Kubernetes distributions, including vanilla Kubernetes (default), Lightweight Kubernetes (K3s), and Zero Friction Kubernetes (k0s).
- A controller manager, which maintains the state of Kubernetes resources like pods, ensuring they match the desired configurations.
- A data store, which is a connection to or mount of the data store where the API stores all resources. By default, an embedded SQLite is used as the datastore, but you can choose other data stores like etcd, MySQL, and PostgreSQL.
- A syncer, which is a component that synchronizes resources to and from the virtual cluster and host cluster and facilitates workload management on the host's infrastructure.
- A scheduler, which is an optional component that schedules workloads. By default, vCluster reuses the host cluster scheduler to save on computing resources. If you need to add node labels or taints to control scheduling, drain nodes, or utilize custom schedulers, you can enable the virtual scheduler.
Syncer
A virtual cluster doesn't have actual worker nodes or a network. Instead, it uses a syncer component to synchronize the virtual cluster pods to the underlying host cluster. The host cluster schedules the pod, and the syncer keeps the virtual cluster pod and host cluster pod in sync.
Higher-level Kubernetes resources, such as Deployment, StatefulSet, and CRDs only exist inside the virtual cluster and never reach the API server or data store of the host cluster.
By default, the syncer component synchronizes certain low-level virtual cluster Pod resources, such as ConfigMap and Secret, to the host namespace so that the host cluster scheduler can schedule these pods with access to these resources.
While primarily focused on syncing from the virtual cluster to the host cluster, the syncer also propagates certain changes made in the host cluster back into the virtual cluster. This bi-directional syncing ensures that the virtual cluster remains up-to-date with the underlying infrastructure it depends on.
You can configure what and how the syncer synchronizes to and from the host cluster depending on your use case.
How does syncing work?
Syncing is the process where vCluster copies a resource between the virtual cluster and the host cluster. It's the basic principle vCluster uses to emulate a fully functional Kubernetes cluster.
vCluster only syncs low-level resources by default, such as pods, secrets, configmaps or services. As soon as one of these resources are created in the virtual cluster, vCluster will sync it to the other side. As soon as a resource was copied by vCluster, it will start watching for changes to the resource on either side, so when a controller changes something on the host cluster side, the vCluster will sync that change to the virtual cluster or when a change on the virtual cluster side happens, it will sync it to the host cluster, to make sure the resource is in sync.
Let's take Ingress as an example. A user that creates the following ingress in the virtual cluster:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx
spec:
tls:
- hosts:
- https-example.foo.com
secretName: testsecret-tls
rules:
- http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: nginx
port:
number: 80
When copying to the host cluster, the vCluster will change the ingress to:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
vcluster.loft.sh/object-host-name: nginx-x-default-x-vcluster
vcluster.loft.sh/object-host-namespace: vcluster
vcluster.loft.sh/object-kind: networking.k8s.io/v1, Kind=Ingress
vcluster.loft.sh/object-name: nginx
vcluster.loft.sh/object-namespace: default
vcluster.loft.sh/object-uid: bb8bea39-8c0c-4295-8616-6a20b3b1900a
labels:
vcluster.loft.sh/managed-by: vcluster
vcluster.loft.sh/namespace: default
name: nginx-x-default-x-vcluster
namespace: vcluster
spec:
rules:
- http:
paths:
- backend:
service:
name: nginx-x-default-x-vcluster
port:
number: 80
path: /
pathType: ImplementationSpecific
tls:
- hosts:
- https-example.foo.com
secretName: testsecret-tls-x-default-x-vcluster
There is a couple of important changes to be noticed:
- Name Rewritten: vCluster rewrites the name of the resource to avoid conflicts in the host cluster. The name is rewritten in the form of
NAME-x-NAMESPACE-x-VCLUSTER_NAME - Namespace Rewritten: vCluster rewrites the namespace of the resource to sync everything into the vcluster's namespace.
- Annotations / Labels Added: vCluster adds annotations and labels to identify the resource in the host cluster.
- References Rewritten: vCluster rewrites the
spec.rules[*].http.paths[*].backend.service.nameandspec.tls[*].secretNameto match the rewritten names of the resources in the host cluster.
vCluster will also keep track from now of the resource within its internal name cache, that tracks the VIRTUAL NAME <-> HOST NAME as well as all references used by this resource. In the ingress case, this would be the service nginx and the secret testsecret-tls. Tracking references helps the vCluster to understand what resources are still needed in the host cluster. For secrets and configmaps this is important, because by default only the needed ones are actually synced to the host cluster.
Host cluster and namespace
Each virtual cluster runs as a regular StatefulSet (default) or Deployment inside a host cluster namespace. Everything that you create inside the virtual cluster lives either inside the virtual cluster itself and/or inside the host namespace.
It is possible to run multiple virtual clusters inside the same namespace. You can even run a virtual cluster inside another virtual cluster, otherwise known as vCluster nesting.
For certain cases that don't require strong isolation, you can run workloads in multiple underlying host namespaces. However, this feature is experimental and requires more management overhead.
Networking in virtual clusters
Networking within virtual clusters is crucial for facilitating communication within the virtual environment itself, across different virtual clusters, and between the virtual and host clusters.
Ingress traffic
Instead of having to run a separate ingress controller in each virtual cluster to provide external access to services within the virtual cluster, vCluster can synchronize Ingress resources to utilize the host cluster's ingress controller, facilitating resource sharing across virtual clusters and easing management like configuring DNS for each virtual cluster.
DNS in virtual clusters
By default, each virtual cluster deploys its own individual DNS service, which is CoreDNS. The DNS service lets pods within the virtual cluster resolve the IP addresses of other services running in the same virtual environment. This capability is anchored by the syncer component, which maps service DNS names within the virtual cluster to their corresponding IP addresses in the host cluster, adhering to Kubernetes' DNS naming conventions.
With vCluster Pro, CoreDNS can be embedded directly into the virtual control plane pod, minimizing the overall footprint of each virtual cluster.
Communication within a virtual cluster
Pod to pod
Pods within a virtual cluster communicate using the host cluster's network infrastructure, with no additional configuration required. The syncer component ensures these pods maintain Kubernetes-standard networking.
Pod to service
Services within a virtual cluster are synchronized to allow pod communication, leveraging the virtual cluster's CoreDNS for intuitive domain name mappings, as in regular Kubernetes environments.
Pod to host cluster service
Services from the host cluster can be replicated into the virtual cluster, allowing pods within the virtual cluster to access host services using names that are meaningful within the virtual context.
Pod to another virtual cluster service
Services can also be mapped between different virtual clusters. This is achieved through DNS configurations that direct service requests from one virtual cluster to another.
Communication from the host cluster
Host pod to virtual cluster service
Host cluster pods can access services within a virtual cluster by replicating virtual cluster services to any host cluster namespace. This enables applications running inside the virtual cluster to be accessible to other workloads on the host cluster.